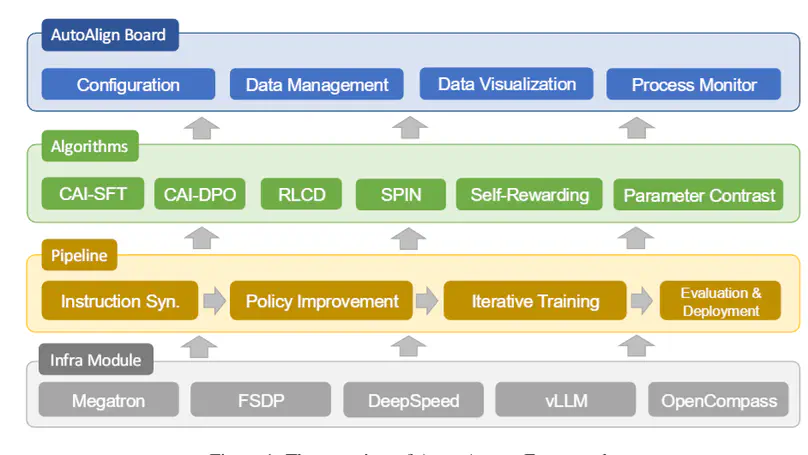
An open-source toolkit for automated alignment of Large Language Models with human intentions and values.
We propose ShortV, a training-free method that reduces computational costs of MLLMs by freezing visual tokens in ineffective layers.
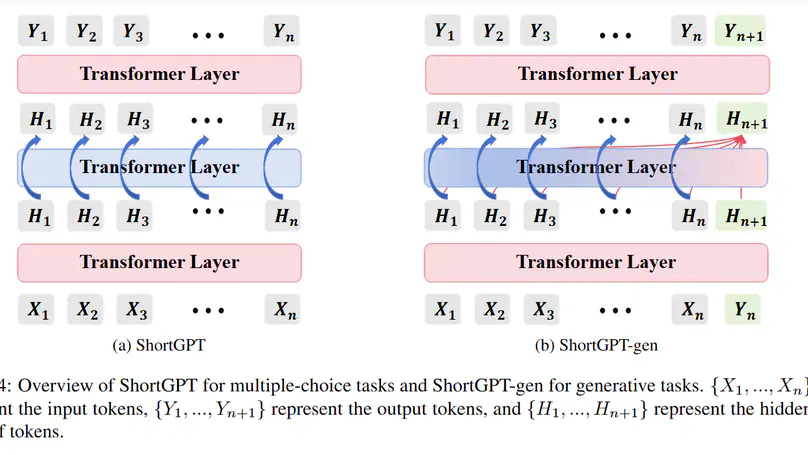
We investigate the redundancy within Transformer layers and propose an effective layer-based pruning method.
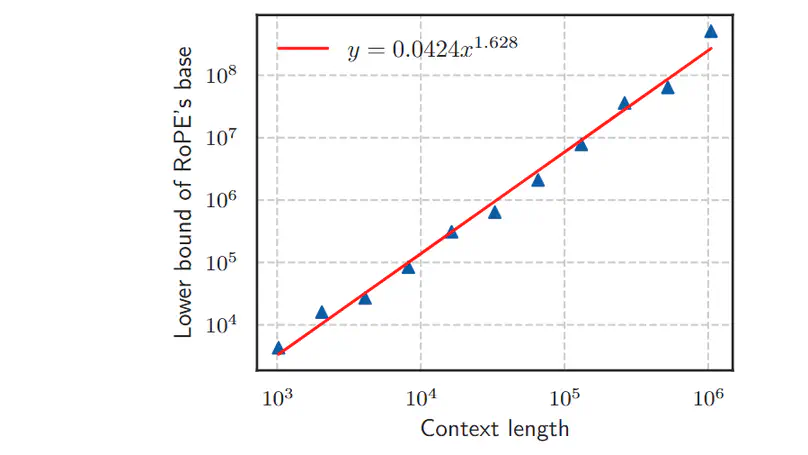
This work contributes to the investigation of the lower bounds of the Base in RoPE, providing a theoretical foundation for the long-context extrapolation of models.